
What makes Prepona a reliable, flexible and complete solution?
We invite you to read through detailed descriptions of our platform on three of its most important verticals: Different Test Types, Setting Up your Own Certifying Body and IRT & Distractor Analysis. Enjoy and please do not hesitate to contact us for further information.

Different Test Types
Proportion Correct
In the name of fair play, certifying bodies should use the same “yardstick” to measure different competency levels for people in a group. Therefore, the yardstick’s consistency and accuracy is an important factor. The yardstick may need to be used over a period of time – years in the case of professional certification programmes. In this case, the question of the quality of this yardstick becomes very important, because it has to be consistent over the long term. This is why Prepona® is committed to quality in the construction and application of distance testing. For the same reason, it puts great effort into every calibration (see our Statistical Analysis and IRT service). The types of proportion correct tests offered include:
Traditional Multiple Choice
Proportion correct multiple choice tests are the most commonly applied type of test and meet the requirements of most customers. The customer determines the number of correct answers needed for the candidate to pass and the results are interpreted based on this simple requirement. This type of test is used when there is insufficient data to calibrate the items. Consequently, it is most often used by Prepona® in the construction and application of simulation tests, where the aim is to calibrate the items to be used in the certification examination (see our Simulation Test service).
Multiple Choice with Similar Psychometric Values (Calibrated Items)
This version of the proportion correct multiple choice test has several advantages because using a large bank of calibrated items, and in accordance with the customer’s predetermined parameters, we can produce millions of test combinations with similar psychometric values. This process allows the examination to be given 365 days a year while, at the same time, helping preserve its integrity since every test consists of different items, thus reducing fraud. Furthermore, banks containing items with similar psychometric values help ensure that all tests are of the same difficulty level, meaning fairer candidate assessment.
Multiple Choice Divided into Modules, Domains and/or Sub-domains (with Calibrated Items)
This version also allows for the construction of tests that assess the level of knowledge in several distinct areas in just the one test, without undermining the production of results. Prepona® will supply the customer with statistical data which will indicate the areas in which the candidate is weak or strong. This option is used by one of the largest certification programs in Brazil.
Computer Adaptive Test (CAT)
This type of test is highly recommended for the assessment of a knowledge area because of the highly accurate results it generates, and consequently the reliable competency level of the person tested. This is why it is the preferred option for the majority of the most respected certifying bodies worldwide.
The fact that the candidate has to answer fewer questions obviously significantly reduces the length of the test, as well as bringing a further considerable benefit: when the candidate is answering questions that are more in line with their knowledge level, their concentration level is at its peak. This improves the quality of the information yielded by the assessment and consequently improves the quality of any decisions taken based on the test result.
The test program interprets this data to make a dynamic assessment of the candidate (according to their replies) and after only 5 or 6 questions have been answered, it is already able to select items from the bank that best discriminate at that difficulty level. As soon as the responses start to fit in with the predetermined correct response probability for a candidate at that level of difficulty, the assessment ends. In practice, this means that an accurate level can be produced in around 40 items.
Another benefit of this system concerns security. The test content is not repeated from one candidate to the next unless they receive an identical series of initial questions and answer them all the same way, which although not impossible, is statistically most unlikely.
Finally, the application of a CAT allows new items to be calibrated for use in future tests. In other words, without realizing it, candidates answer a few items that do not count towards the assessment of their competency level. This calibration process, which involves the target public, is of great benefit to customers of Prepona®.
In conclusion, a CAT test gives the best parameter possible in terms of result accuracy, consistency and integrity, as well as reducing the possibility of fraud. The CAT test also reduces the candidate’s level of stress, which must always be an important factor for any certifying body that is striving for quality in its program.

How to set up a certifying body
Precepts
All the necessary guidelines for setting up a certifying body have already been written. These important, realistic and sensible guidelines can be found in standard ISO 17024 and its precepts of common sense:
fairness
competence
responsibility
transparency
confidentiality
prompt replies to complaints or appeals

However, it would be good to start with what we at Prepona®, understand by the phrase "people certification":
“The periodic assessment of knowledge, or skills, to show that these are up-to-date”
The frequency of the people certification or recertification process may depend on the field of activity and the two largest certification processes in the world – Information Technology and Nursing – demonstrate this difference.
Certification in the IT field is, correctly, based on highly specific knowledge and the validity of examinations in this area reflects this. In other words, it is possible to be certified in Office 2003, or in Office 2007, for example. This type of certification reflects the product which doesn’t change – Office 2007 is considered to be a different product to Office 2003. However, in spite of this, Microsoft still imposes a validity period. In nursing, the focus is on the change/progress in the technology and practices in a certain area. For example, a nurse who specializes in cardiology in England must undergo a certification process every two years because “things change” quickly. Generally, however, a certification examination remains valid for 4 or 5 years.
In any case, certifying bodies that have adopted the ABNT/ISO 17024 precepts offer their examinations to everybody.

“Guaranteeing good governance, avoiding conflicts of interest.”
- Another important goal of a Certifying Body (CB)
Correct Structure
The certifying body’s structure and documentary base are of utmost importance for achieving this goal.
The independence and integrity of the certifying body must be recognized by all. In the absence of a regulatory framework, perhaps the best way of achieving independence is through a decision of the board of directors or governing body giving “their blessing”. In other words, recognition by the board of directors or governing body will provide all the necessary grounds that your certifying body will need. Once this has been obtained, the essential structure to be set up consists of:
Certification Committee
Certification Subcommittees (if there is more than one certification area)
Appeals Committee
It is the Certification Committee that has the “power” in this process and it must be independent of pressure from other areas of the bank. This committee calls the shots, but it must do so responsibly and transparently, avoiding conflicts of interest – nothing more, nothing less than good governance.
The Certification Committee will contract the content providers, the technological partners (such as Prepona®) and your test-center logistics partners. The committee must demand quality and integrity (against fraud) from all its partners, while always ensuring that candidates receive a quality service.
Setting up Subcommittees is also recommended (one for each certification), thus leaving the Certification Committee to operate as the executive power. The Appeals Committee must also be ready to spring into action. Certification is a serious business, and the rights of candidates must all be protected. This is why a formal appeals structure must be available.
Necessary Documents
As well as the structure, the following documents are essential for a Certifying Body:
Regulations (and in some cases, the regulatory framework)
Candidate Manual
Code of Conduct
User Manual for the Certification Stamp or Mark
In accordance with ISO 17024, the rules of a certifying body (CB) must be completely and clearly specified.
The CB’s main document is the Regulations, as this contains all the rules not only of the game, but also of the entire championship. It must detail everybody’s rights and responsibilities. It is usually convenient to include the Code of Conduct (see below) as part of this document. When somebody registers in a certification program, they must accept the terms of this document (which may be done electronically using your certification system).
The Candidate Manual explains the rules of the game, that is, how they apply to each certification. In reality, less than 10% of this manual changes from one certification to another. This manual includes everything from the bibliography (the knowledge base to be assessed) to the candidate’s behavior at the test center and the materials they may or may not use when sitting the examination (for example: an HP financial calculator is allowed, a mobile phone is not, etc.). On booking their examination, the candidate must accept the terms of this document (which may be done electronically using your certification system).
The Code of Conduct must be presented twice during the process because before passing the test, the person is a “candidate”, and later becomes a “certified person”. The first occasion is usually at the registration stage, which is why it is very often included in the Regulations. The second time a person has to accept the code is when they receive the wonderful news that they have passed the test and want to receive their certification! The two identities are slightly different.
The User Manual for the Certification Stamp or Mark contains the rules for using the stamp (in email signatures or on business cards, etc.), as well as printing instructions.
There are still two more important documents: the Certificate itself and the Spokesperson Policy.
Paper is one of the easiest things to forge. How many fake diplomas are there? A lot! This is why certifying bodies usually require that the authenticity of a Certificate be checked on their website. We can show you how to develop a “window” in a system which everybody can use to display the digital version of their Certificate.
If you want to issue paper certificates, they must contain whatever is necessary to protect the integrity of your certification program.
A CB should also have another document which, like the Code of Conduct, applies to everybody involved (executives, employees, staff, partners, candidates, certified people, etc.). This document is called the Spokesperson Policy.
Finally, there are three documents that are important at the operational level. These are:
1. Guidelines Agreement (signed by the candidate at the test center)
2. Confidentiality Agreements (signed by all the partners)
3. Test Center Manual (for the test centers)
The Guidelines Agreement must be signed by the candidate and the proctor when the candidate arrives to sit their certification examination. Amongst other things, this document acts as proof that the person was present for auditing purposes.
The Confidentiality Agreements are documents that are usually signed by the Certification Committee and its partners (content providers, technological partners and logistics partners) and even between them. For example, Prepona will sign a Confidentiality Agreement with the content providers.
The purpose of the Test Center Manual is to provide test centers with guidelines about the certifying body’s examination or examination suite.
After signing a contract with its customers, Prepona® will provide all the help necessary to develop the structure and documentary base, to meet the demands of standard ISO 17024. The templates for all the documents will be provided free, thus enabling them to be developed quickly, as well as representing huge savings in legal and consultancy fees.
Processes and Procedures
Given that the Prepona® system processes and procedures already meet the strictest requirements (even those in the ISO/IEC 23988 standard), all a certifying body needs to do is implement some of the ISO 9001:2008 standard’s processes and procedures to enable it to go through the ISO 17024 accreditation process.

Item Response Theory and Distractor Analysis
The Importance of Ensuring Assessment Quality in People Certification Processes
For certification processes which involve large-scale knowledge assessment and which, by definition, run for years, it is essential to ensure the quality of these processes. In other words, any certifying body must ensure not only the integrity of its examinations (especially against attempted fraud), but also the consistency of the “yardstick” that is used.
The certifying body must make the maximum effort to guarantee all certification candidates a level playing field over the years (to ensure fair play). This is why a traditional multiple choice test, with new items (questions + correct answer + incorrect answers) written every year by a group of content developers, who are often instructors, can create problems, because there is always one difficult question to be answered: “Who can guarantee that the test applied in any given year is equal, or sufficiently similar, to the test applied in other years?” That is to say: is the same “yardstick” being used? Have we suddenly stopped using imperial units and adopted the metric system?
In any event, there are several good arguments against using a multiple choice test. One thing that we at Prepona have learnt is the need to keep an open mind (and not fall victim to obsessive biases) when selecting the best assessment tool for achieving the goals of the certifying body. The choice of one of the many types of multiple choice test (including Computer Adaptive Testing), or a discursive test, or even a task fulfillment assessment, will depend on the number of candidates, the resources available (the number of examiners, for example) and the goals of the certification process.
Returning to the use of multiple choice tests, we are not going to focus necessarily on the intrinsic value of this type of assessment but, based on the assumption that a multiple choice test is suitable for the certifying body’s goals, we would like to look at the things that can be done to ensure the quality of the “yardstick” to be used.
To sum up: what can be done to ensure the quality of the items and, consequently, of all the certification process? One way is to submit all the items to be included in a test’s item bank to a “validation” process. This process involves a statistical analysis which in the testing industry is called “calibration”. The most effective calibration method is based on Item Response Theory (IRT).
Item Response Theory (IRT)
Item Response Theory (IRT) represents the mathematical interface between the candidate and the item. It is rooted in Loevinger’s[1] ideas which state that all the items in a test must measure the same thing, or the same latent trait. IRT formalizes this explicitly by assuming that there is just a single dimension for measuring the knowledge or skill that is required to answer all the test items correctly. Examples of these characteristics include:
· Linguistic competence
· Mathematical skills
· Logical reasoning
The position that each item occupies on this dimension is called the item difficulty and is called the b parameter.
The position of each candidate on this dimension, which measures their competence or skill, is usually positioned on a scale called the θ scale.
The IRT model gives the probability that a candidate whose competency level is θ will correctly answer an item of difficulty b. In its simplest form, IRT combines just these two variables, and as it is defining the item using only 1 parameter (the difficulty, b), it is called the 1 Parameter Logistic Model (1PL).
This model is also called the Rasch model after Georg Rasch[2], who developed it in 1960.
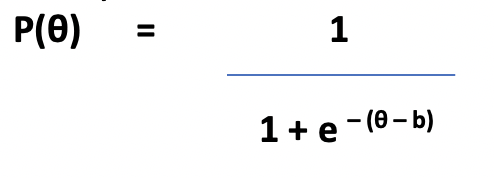
[1] Loevinger J. A systematic approach to the construction of and evaluation of tests of ability, Psychological Monographs, 61, 4 – A demonstration that all the items in a test must measure the same characteristic – that is: the test must be homogeneous.
[2] Rasch – Probabilistic models for some intelligence and attainment tests. Copenhagen: Denmark Paedagogiske Institut.
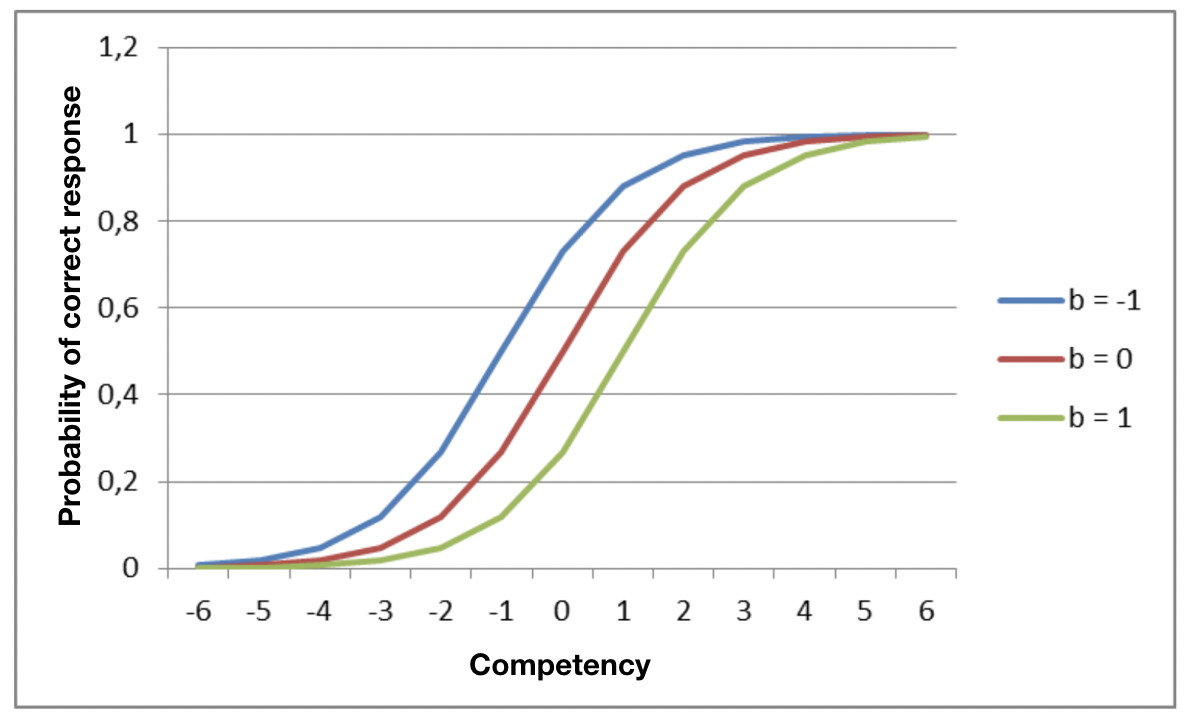
The graph shows the structure of this model for three items of different difficulty levels.
These graphs are called Item Characteristic Curves (ICC)
For the most part of the curve, the ICC of the items are more or less parallel. Unfortunately, this approximation means that in many cases the model fails, because the behavior of the ICC is not well described by the model. There are two options for dealing with these cases: we can remove items whose behavior diverges from the model from the item bank, or we can generalize the model to accommodate different gradients. This is done by including a second parameter for each item. This parameter, called a, reflects the slope of the ICC and measures the item’s discrimination. The resultant mathematical model, called the 2 Parameter Logistic Model (2PL) is now represented:
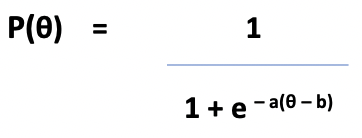
Once again, a graphical representation helps make things clear. Consider the graph on the right, which shows the ICC of three items with the same b value – one item that discriminates very well (a = 2), one that is average (a = 1), and one that discriminates weakly (a = 0.5).
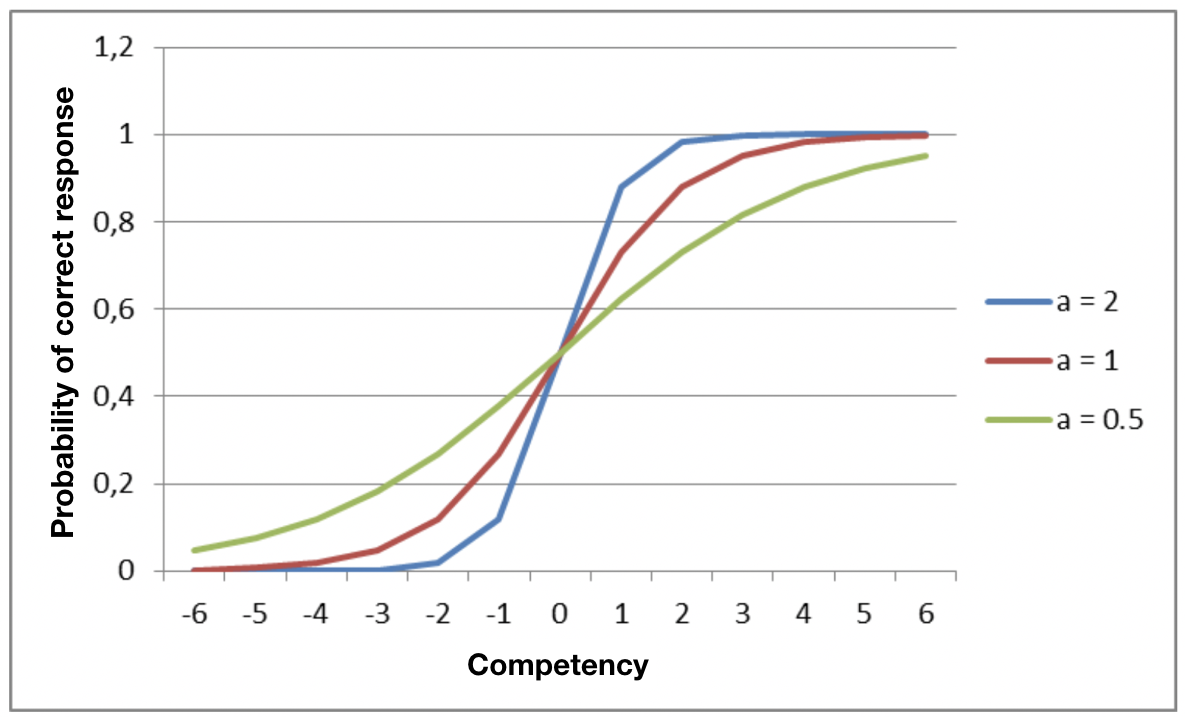
The addition of this parameter greatly increased the applicability of IRT. However, there is still a further factor to be considered: for multiple choice tests there is always a significant possibility of a candidate guessing the correct answer. Neither of the models described above take this possibility into account: there are two reasons why a candidate may answer an item correctly which is way beyond their competency level – the test is not unidimensional and the item was answered using knowledge from a different knowledge base to the one being tested, or the candidate simply guessed. In this case, we could simply eliminate these items, but it is unlikely that this type of correction would work because different candidates would guess different items correctly and we would end up removing all the difficult items from the test! A second solution is to generalize the model so that it accounts for guesswork. The resulting model, as described by Lord and Novick[1], is called the 3 Parameter Logistic Model (3PL), and is described by the equation below:
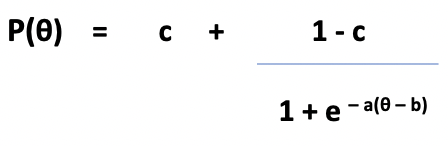
[1] Lord & Novick (1968) – Statistical Theories of Mental Test Scores. Reading. MA Addison-Wesley.
Once again, the structure of the 3PL can best be represented graphically (see left).
The 3PL model is the IRT model most used for large-scale testing. In fact, the pseudo guessing parameter (c) is rarely needed in the context of Computer Adaptive Testing (CAT) because, if the test is working correctly, candidates will seldom encounter items that are very difficult for them. It is, however, very necessary during the calibration stage at the start of the test development process.
In conclusion, there are several advantages from validating the items in a test using IRT, not only for the construction and application of a CAT test but also for proportion correct multiple choice tests.
If we know the values of the items’ parameters, we will have a reliable yardstick for measuring candidates’ skills or competencies.
Competency or Skill Estimates
Once an item bank has been developed with the items’ a b and c values duly calculated, we can apply the test to our candidates, and calculate their competency level (θ) using the maximum likelihood method.
Let:

This equation simply represents the product for a candidate of competency level θ correctly getting right the items that they did get right, and getting wrong the items that they did get wrong, for all items. Once again, a graphical representation helps make thing clear.
Consider a two-item test, where the candidate answers the first question correctly and the second item incorrectly:
For a given candidate, therefore, the competency level or maximum likelihood is represented by the maximum of the probability graph. Clearly, in the case of a two-item test, the distribution of the graph is very wide. However, as we apply more items, we will see that the estimate starts to taper. In the example (right), the candidate got 12 items of a twenty item test correct, and the other 8 wrong.
This tapering enables CAT technology to be used to make test application more, let’s say, “intelligent”.
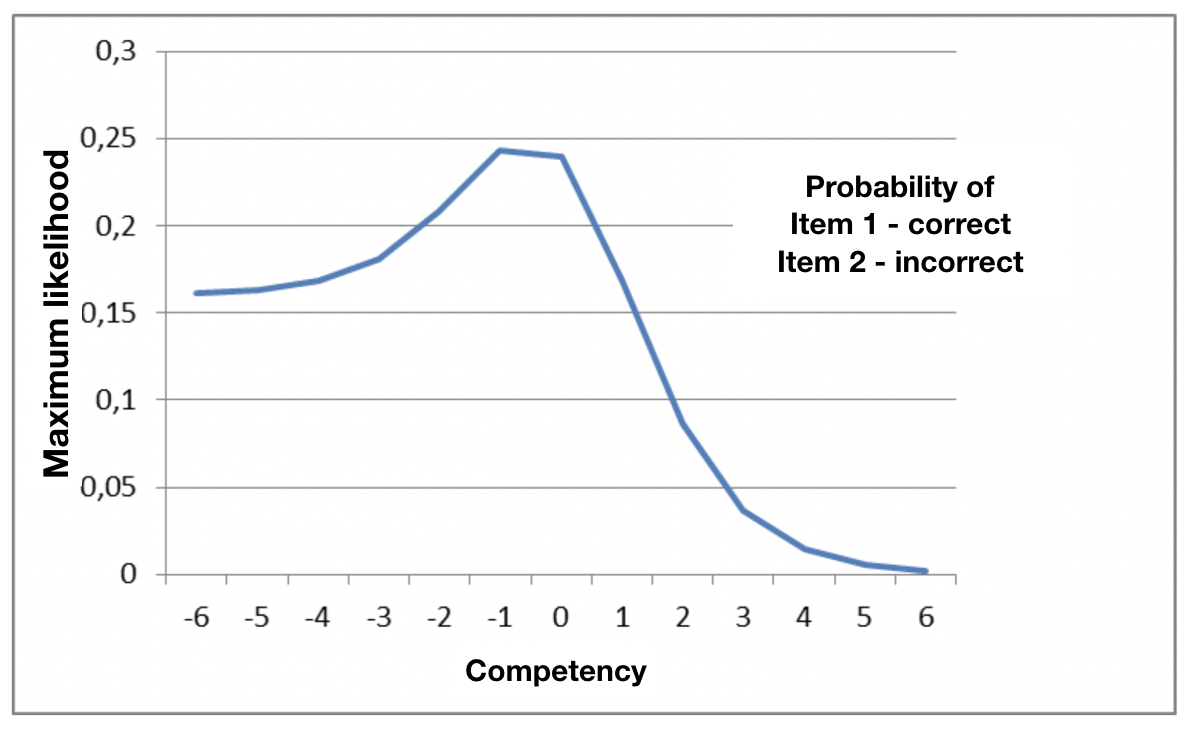
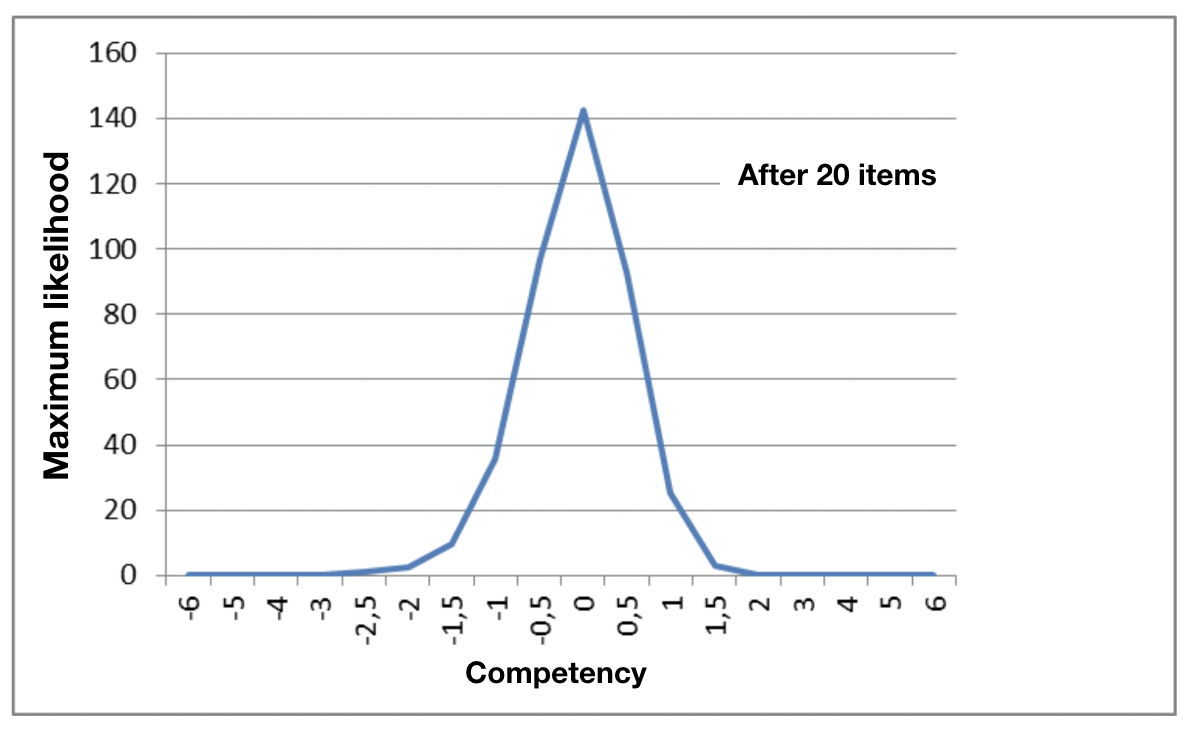
IRT and CAT Tests
A CAT test uses an algorithm which always aims to apply the items that provide most information about the candidate. If, for example, we apply a series of very easy items and the candidate gets them all correct, we learn very little about their competency level. If, on the other hand, we apply a series of items that are too difficult, the candidate’s only resource will be to guess and once again, we will learn very little. A CAT selects the items with the aim of tapering the graph as much as possible, and therefore enabling a more accurate assessment with fewer items.
This factor enables the test to gradually focus on items that are closer and closer to the candidate’s true competency level, and progressively eliminates the need to apply items that are either too easy or too difficult. The great benefit for the candidate is:
Each candidate will feel that the test was “customized” for them with a reduction in stress (brought about by their being presented with items that are too difficult) and/or boredom (caused by their being presented with items that are too easy). This reduction in stress is an important factor in certification processes which are by their very nature highly stressful experiences, as passing the test is often a requirement for getting or keeping a job.
We can apply fewer items in total while, at the same time, applying more items around the candidate’s true competency level, thus ensuring a more accurate result (because we test a candidate much better using items of around their level), and also reducing the total time of the process. This reduction in test time is also a factor for stress reduction, because nobody enjoys spending half a day in a situation that demands as much concentration as taking a formal test.
A good example of how a CAT test can reach a more accurate result in fewer items can be clearly seen in the log file of a real English test produced below:
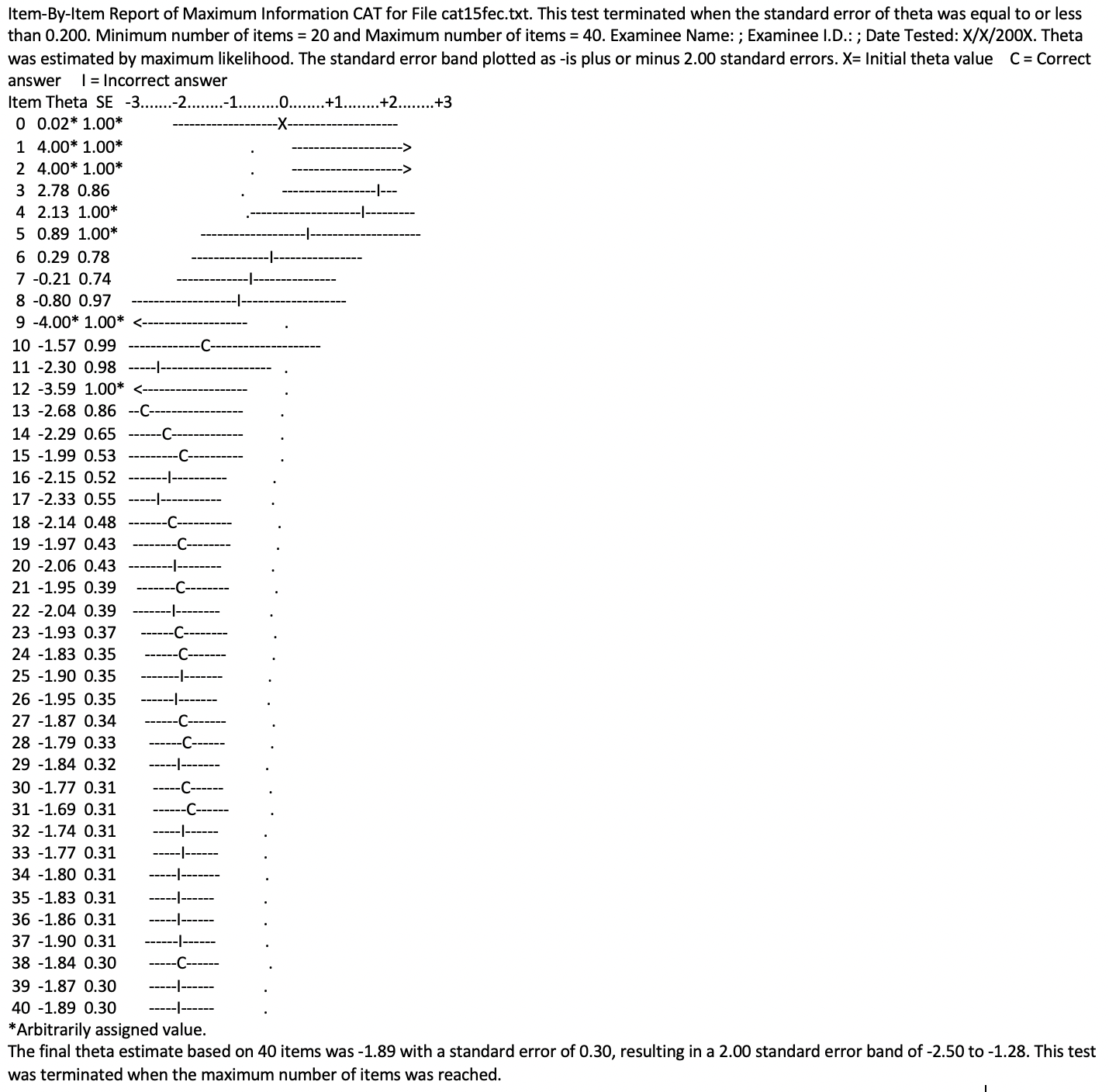
Before adopting CAT, Prepona applied proportion correct multiple choice tests as part of its English assessment procedure. Given that a test of this nature must aim to reflect the real teaching situation, we were obliged to try and place a person on one of ten possible levels! To do this, we used to give a multiple choice test containing 120 items. This enabled a maximum of only 12 items per competency level to be presented.
By adopting CAT, we are able to find the candidate’s level using far fewer items, while at the same time, presenting them with many more items around the candidate’s competency level. The log file above shows that the candidate answered a total of 40 items, six of which were selected arbitrarily, the reasons for this are discussed below. The important thing is that even though fewer items were applied, many more of them (36) were around the candidate’s real competency level, thus enabling a much more accurate result to be produced.
In conclusion, the increased accuracy of the final result – the candidate’s competency level – and the reduction in stress re two of the main factors for adopting the CAT methodology in people certification processes.
The fact that a certifying body has used IRT to calibrate its item bank and uses CAT to apply tests helps it to maintain the integrity of test content. If the next item to be presented to a candidate is selected as a result of the response(s) given to the previous item(s), a “weak” candidate, for example, will never see the items to be given to a “stronger” candidate, and vice versa.
The fact that this generates a feeling among candidates that the test has been “customized” for each of them also implies much increased security because candidates answer different items in different orders. This helps in the battle against people of malicious intent who are determined to defraud the certification process. To sum up: stress is reduced and security increased.
Another major benefit, or advantage, is that by using items that have been duly calibrated with IRT, the certifying body can ensure that it is maintaining the consistency (quality) of its “yardstick”. If, for example, an item suffers from “over exposure” (in other words: if it is selected too often by the CAT algorithm), it may be substituted by a different item with very similar psychometric (a, b and c) values. In other words: instead of substituting a given item by one selected at random, we are able to choose an item that has the same (or nearly the same) level of difficulty, discrimination, and pseudo guessing parameter. Therefore, the act of substituting items will not affect the consistency of the “yardstick”.
However, these advantages which arise from an IRT analysis process, are not only applicable to CAT tests, they can also bring significant benefits to the wish to guarantee or improve the quality of proportion correct multiple choice tests.
By applying tests applied using calibrated items in conjunction with a computer-based system for item selection based on predetermined parameters, we can greatly increase the number of item combinations possible without jeopardizing the quality of the test as a whole, and with the additional benefit of making attempts to defraud the certification process more difficult. We cannot however reduce the candidate’s level of stress because this type of test requires application of a fixed number of items covering all knowledge levels in a set time.
However, if the certifying body’s goal is to assess different knowledge areas in the same test, for example, or if it is being used to show candidates the areas where they are strong or weak, which can be very useful for directing their future studies, IRT calibrated items have been shown to excellent for guaranteeing the quality of this process.
It will also be possible to withdraw or substitute items just as easily and reliably as for a CAT test.
Going back to the CAT, we would like to talk more about one specific benefit: the combination of an IRT analysis and the CAT methodology allows tests to be used for calibrating new items to be included in the item bank for future use. An analysis of the log file above would reveal that there are six items with no a, b or c values attributed. These items are “seed items”, that is: they are items that have no effect on the assessment process and are only included for calibration purposes. In conclusion, real candidates are used to calibrate new items. Let us then look at the calibration process in more detail.
Item Calibration
As we have seen, every item can be defined by three parameters:
The discrimination (a) – which measures the power of an item to differentiate those candidates who know more from those that know less
The level of difficulty (b)
The pseudo guessing parameter (c) – which reflects the fact that a weak candidate may guess the correct answer to a difficult item
At the beginning of a testing process, we cannot even estimate these values, so it is necessary to gather some data. There are two ways to do this:
Applying simulation tests to future candidates, and/or
Carrying out an IRT analysis of old tests.
Pre-Calibration with Simulation Tests
Once an initial item bank has been developed, several different versions of the test can be prepared where there is some crossover of items. Let us consider a simple case - a bank of 250 items: this can be divided into ten bundles with 25 items in each, and these bundles can be combined to construct ten 50-item test blocks in the following way:
Test Block 1 = Bundle 1 + Bundle 2
Test Block 2 = Bundle 2 + Bundle 3
“ “ “
“ “ “
Test Block 9 = Bundle 9 + Bundle 10
Test Block 10 = Bundle 10 + Bundle 11
More complex systems can be used if necessary, but the important thing is for the tests to be given to candidates of the same level as those that will sit the real test.
Calibration
The parameter estimation process is computationally intensive. We use a program that has been developed specifically for this purpose, which uses an algorithmic approach:
Stage 1 – Initial estimates are calculated based on classical statistical transformations
Stage 2 – These estimates are finely tuned using the Expectation-Maximization (EM)[1] algorithm. The EM cycle is repeated until the parameters remain constant. If there are any items whose values do not converge, the system issues an alert and the item must be analyzed.
NB: If a certifying body has kept hold of earlier examinations and candidates’ responses, we can carry out a calibration process to accelerate the production of key calibrated ready-for-use items.
[1] Dempster, Laird & Rubin - "Maximum Likelihood from Incomplete Data via the EM Algorithm". Journal of the Royal Statistical Society, Series B (Methodological) 39 (1): 1–38 (1977).
Constructing a Proportion Correct Multiple Choice Test
Once the a, b and c values have been calculated, we will know which items are the best to be included in the final test. The test will usually have a profile similar to the one below:
Subject 1: Easy - x1 items, Middling – y1 items, Difficult – z1 items
Subject 2: Easy - x2 items, Middling – y2 items, Difficult – z2 items
Subject 3: Easy - x3 items, Middling – y3 items, Difficult – z3 items
etc...
NB 1: The system can select items at random from those classified within each subject / difficulty level.
NB 2: There may be more than three difficulty levels.
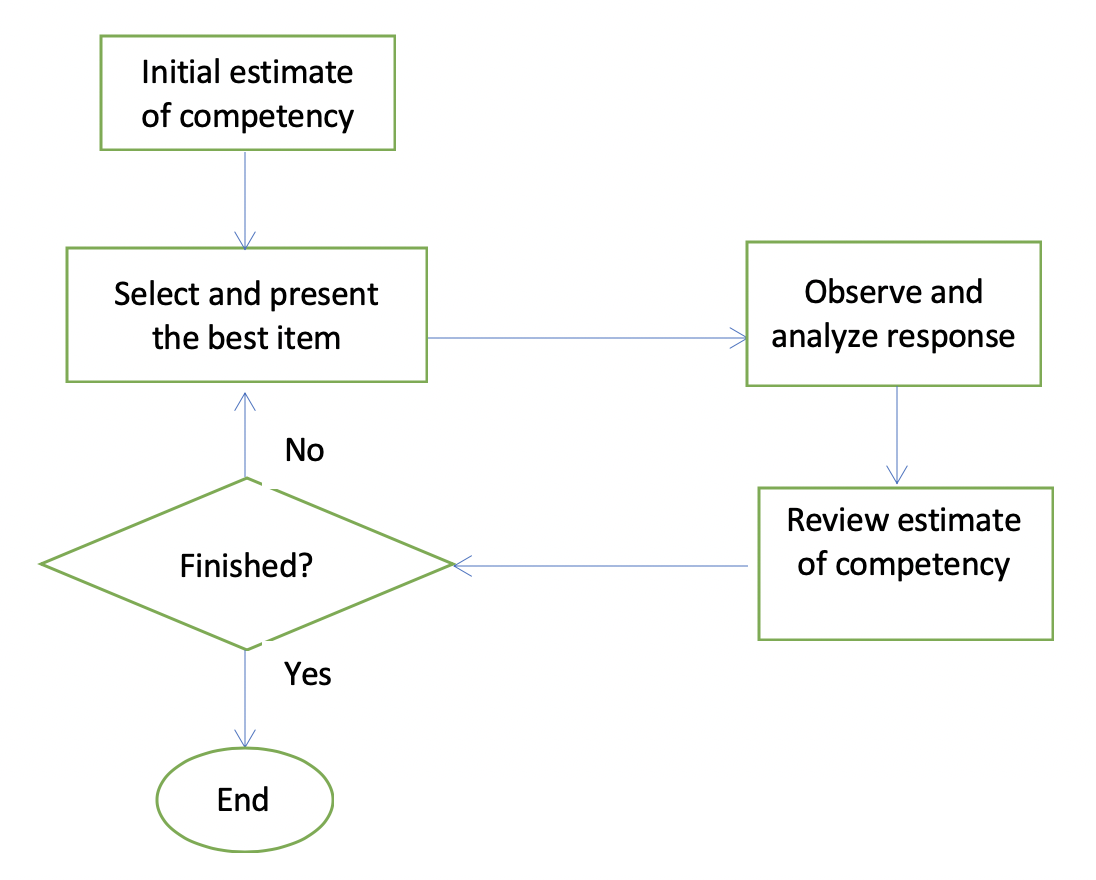
Constructing a CAT Test
In this case all the “approved” items are included in the item bank. The first item is selected in accordance with a predetermined criterion and all subsequent items in accordance with the candidate’s responses to the previous items.
In conclusion, the IRT analysis plays a vital role in the people certification process, because it enables the certifying body to guarantee the market the quality required, regardless of whether the tests are applied using CAT methodology or in the form of proportion correct multiple choice tests.
We have seen that the calibration process must be carried out before the test is launched, but once the item bank has been calibrated and the test is being applied, it is still possible for new items to be included in the bank for future use.
The main advantage of this is that it reduces the workload of the content providers with respect to the production of new items, because we can continue to extract maximum use out of the existing bank with the minimum of maintenance and the maximum of security.
The use of an IRT analysis provides the opportunity to assess different item banks for the same examination or even to compare the examination presented to a particular candidate with those presented to other candidates in the same testing process. This involves the Test Response Function which Prepona can use to help your customers confirm if complaints of the type “my test was more difficult than those of other candidates” are based on fact.
Test Response Function for Test Block Equivalence
Some customers prefer to use several blocks of items when applying their certification tests. They have chosen this option in order to have better control of what is being asked of candidates. IRT is important, firstly, to analyze if there is a homogeneous distribution of items of similar difficulty in all the blocks. In other words: we want to be sure that candidates answering the items in Block 1, for example, do not get a greater number of easy items than candidates answering the items in the other blocks. It is our responsibility, in the name of fairness, to try and ensure that every block presents the candidate with the same challenge. Besides using IRT, therefore, to produce a fair distribution of items in the blocks and ensuring the quality and consistency of the “yardstick”, we can analyze how the blocks compare once the candidates’ responses have been returned. This data can be used to demonstrate graphically the behavior of the blocks and see if any of them deviates from the expected.
The graph on right shows how well grouped the ten blocks used by a certifying body for the same examination. The pass mark for this examination is 70% (35 out of 50).
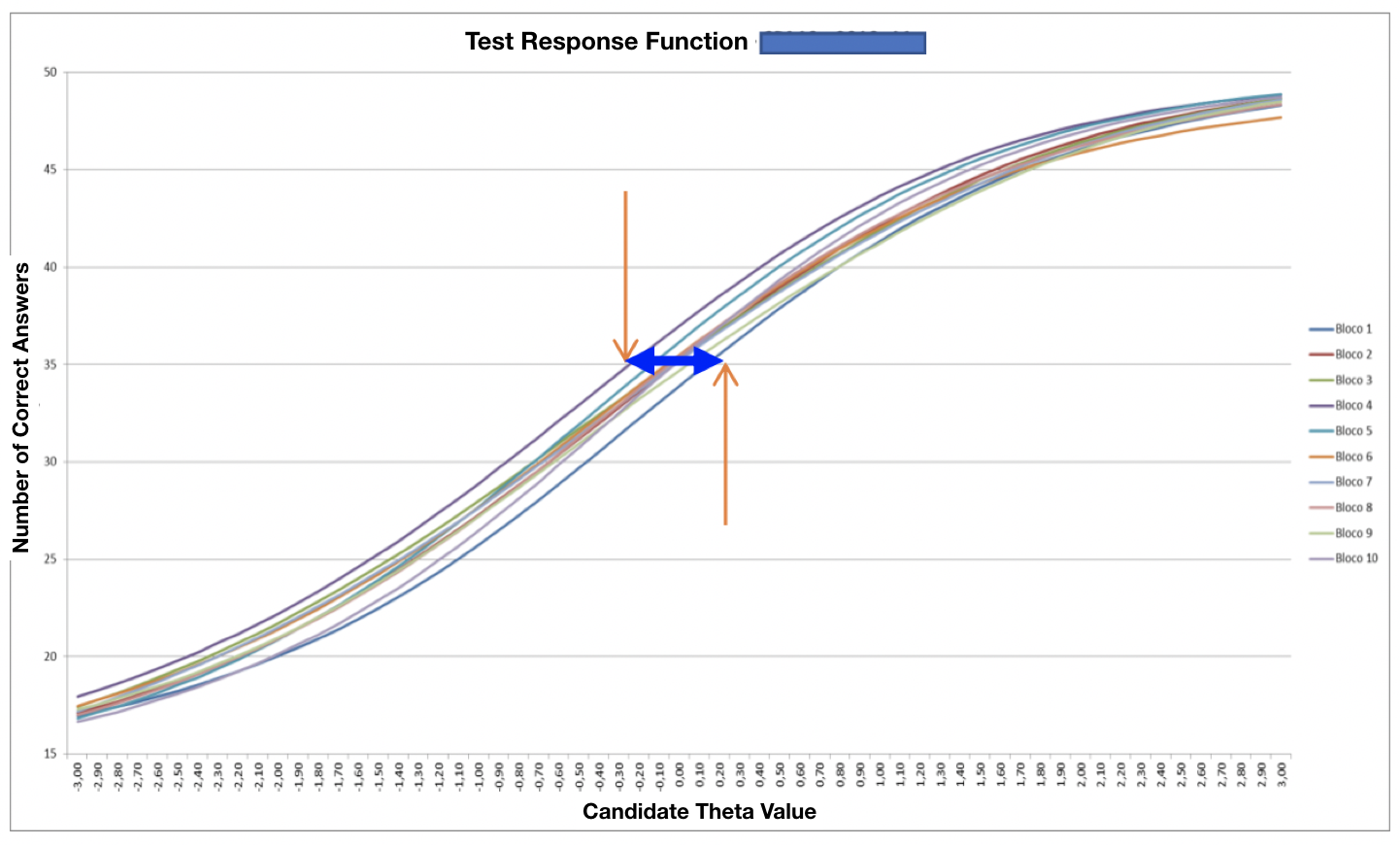
We can see that the curves representing the blocks are very similar to each other, especially in the region of 35/50 correct answers. We can conclude that, in practical terms, no candidate is being unfairly treated through their having received a block (examination) that is more difficult than the rest.
If we look at the item blocks for a second examination, we can see that there may be cause for complaint and, consequently, a need for corrective action. See the graph below, where the pass mark is 42/60:
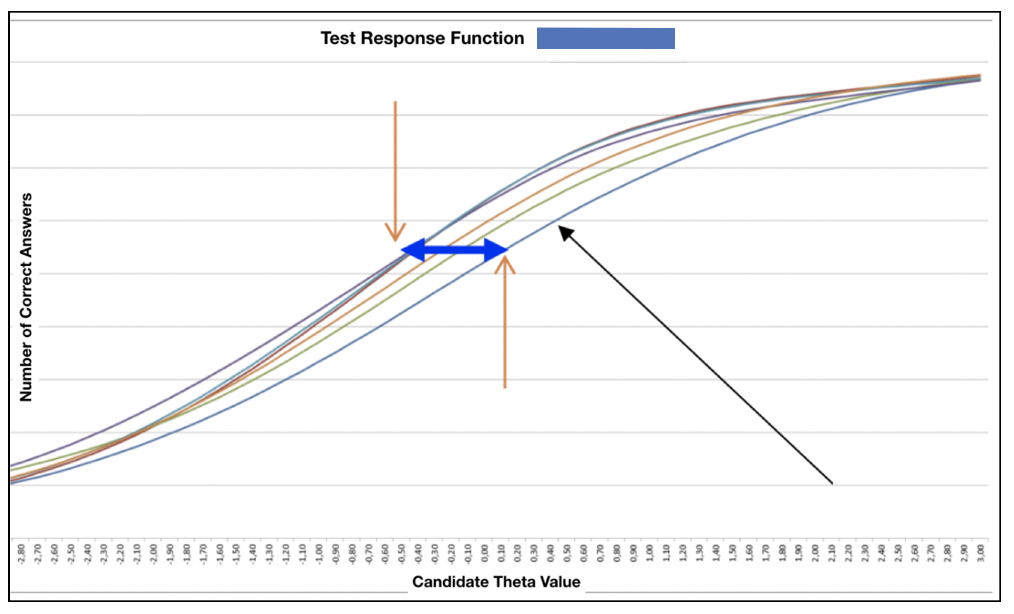
Besides noticing that, in general terms, the graphs are somewhat more scattered, there is one block that is performing very differently from the rest, especially around the pass mark. We can, therefore, recommend careful analysis of the items in this block.
This type of analysis of test block equivalence is to ensure the quality of the examinations that are constructed from different blocks and to respond to formal complaints (through an appeals procedure) or informal complaints (rumors) alleging that some examinations are more difficult than others.
A variation on this analysis can be used for another type of multiple choice examination – a test where the customer does not wish to use fixed blocks but chooses to select items randomly from a large bank, as we show in the next chapter.
Test Response Function for Examination Equivalence
Some customers prefer to use the predetermined parameters to generate an almost unlimited number of tests from the same item bank. IRT is very important in this case and has the benefit of countering any complaints from candidates that they have received an examination that was, in their opinion, more difficult than the examinations given to other candidates. The system can be used to generate a test containing the easiest possible set of items from the item bank, given the predetermined item distribution. Similarly, it can produce the most difficult. We can, thus establish the two extremes of difficulty as well as, logically, the median. Once this has been done, we can process the items in the test given to the candidate in order to compare the “degree of difficulty” of that particular candidate’s test to the average and to the two extremes. See below the graphs of the tests of two candidates:
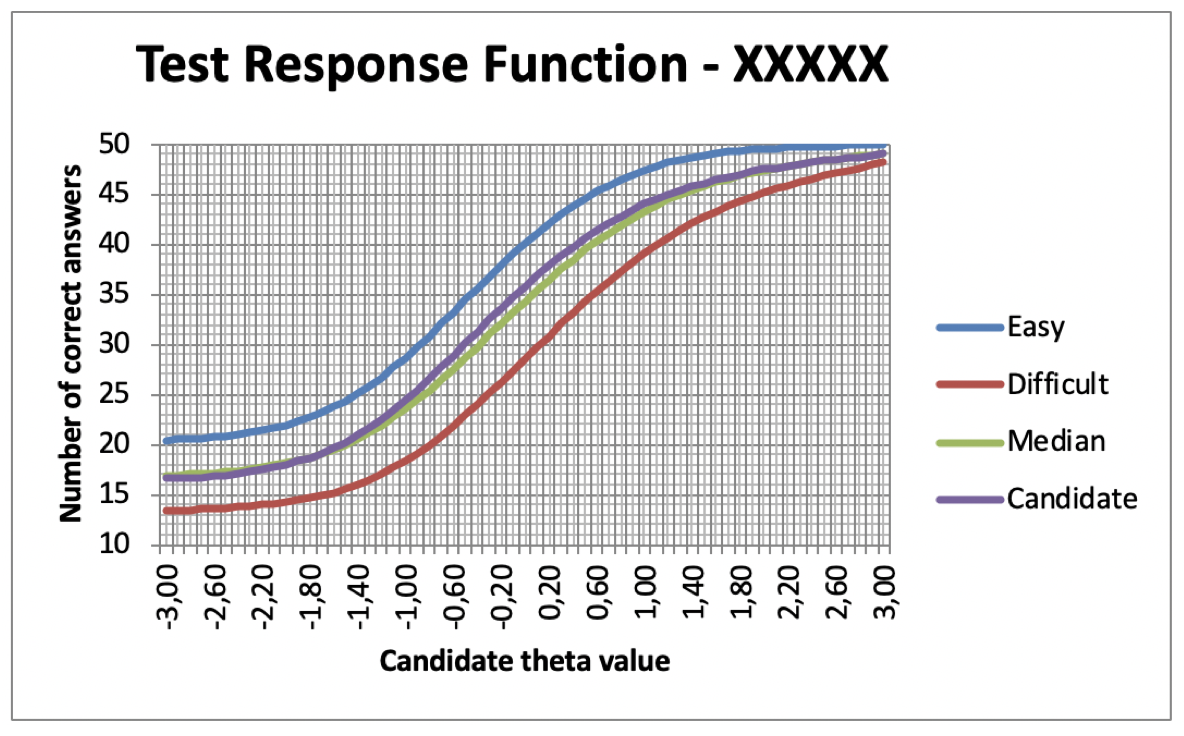
Candidate A
We can see that for most candidates (excluding the very weak), the test given to candidate A was easier (albeit very slightly) that the average. Any complaints of this type are therefore groundless.
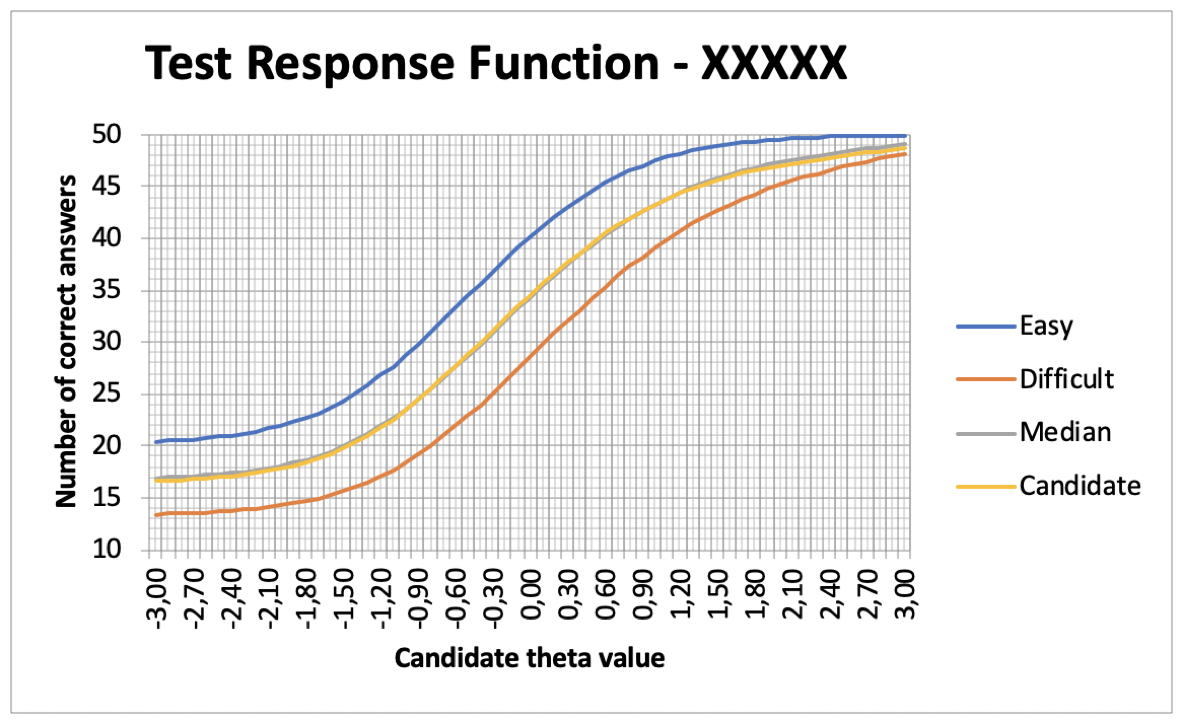
Candidate B
In this case, candidate B also has no grounds for complaint, because the test response function for their test is practically coincident with that of an average test!
This type of analysis is part of the arsenal of data and analysis tools that customers, such as certifying bodies, can use to guarantee the quality of their examinations. All of which are based on an Item Response Theory (IRT) analysis.
As well as using IRT methodology, Prepona can carry out another type of real time analysis aimed an analyzing the performance of the incorrect answers to each item – that is: an analysis at the micro level of how each item is behaving.
We know that the most difficult part in item development is creating the incorrect responses. These incorrect responses are called “distractors”, because their aim is to attract candidates whose competency level is below that necessary to select the correct answer. In other words, we aim to avoid, for example, answers that are so obviously silly that they help a weak candidate to improve their chances of guessing correctly!
Distractor Analysis
Even though the items selected to make up a test have been through a statistical analysis to identify those that best assess the candidates’ competency, it is a good idea to analyze them in greater detail to see how they can be improved.
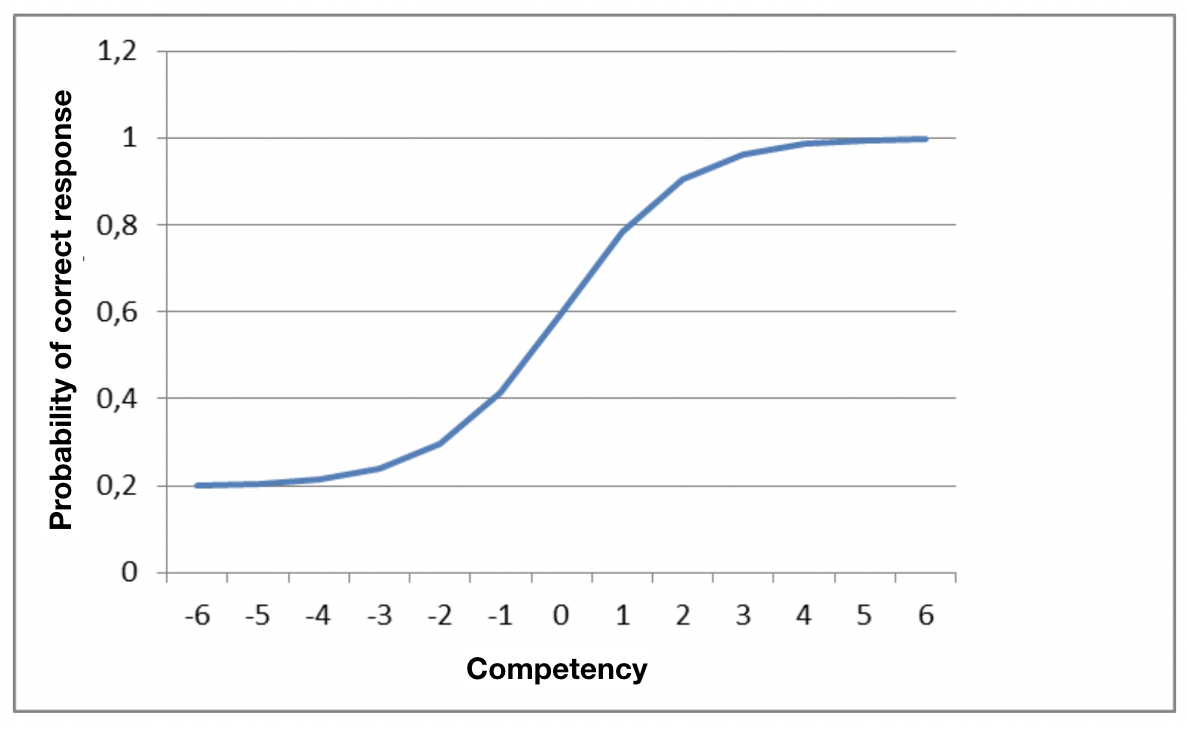
As has already been explained, an ideal item behaves in the way represented below:
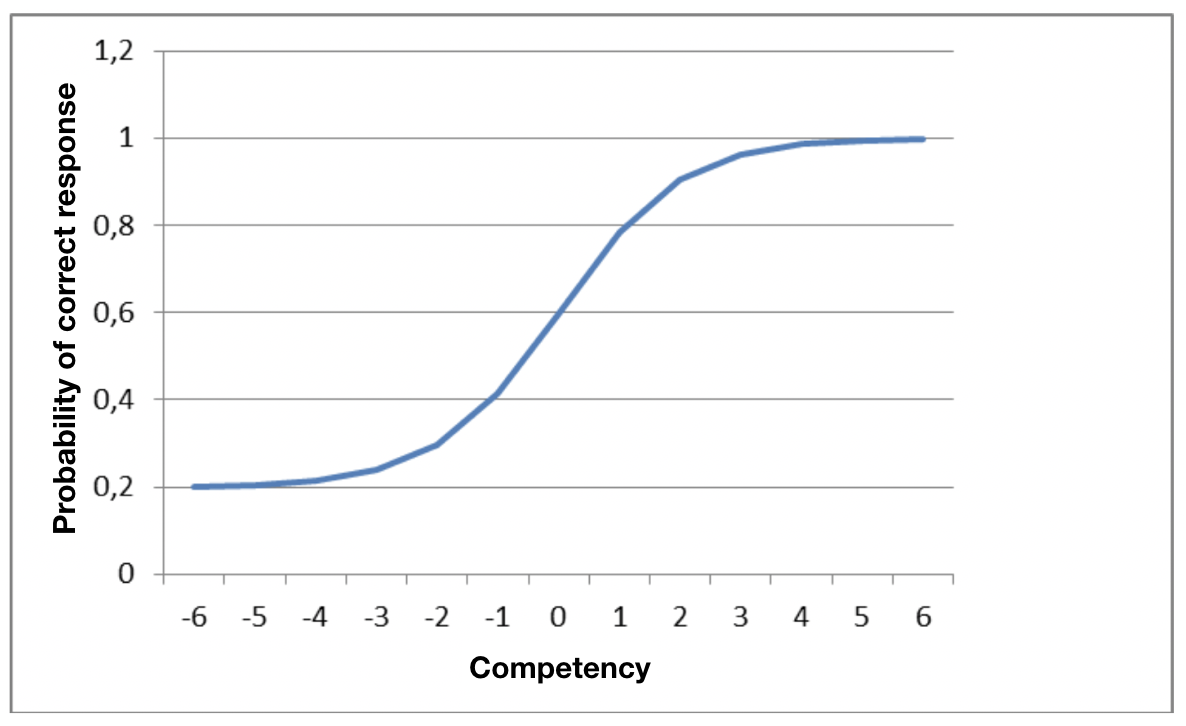
However, it is also important to consider the incorrect options and their behavior. Ideally all the wrong responses will attract a significant number of weak candidates and fewer numbers as the candidates’ competency rises.
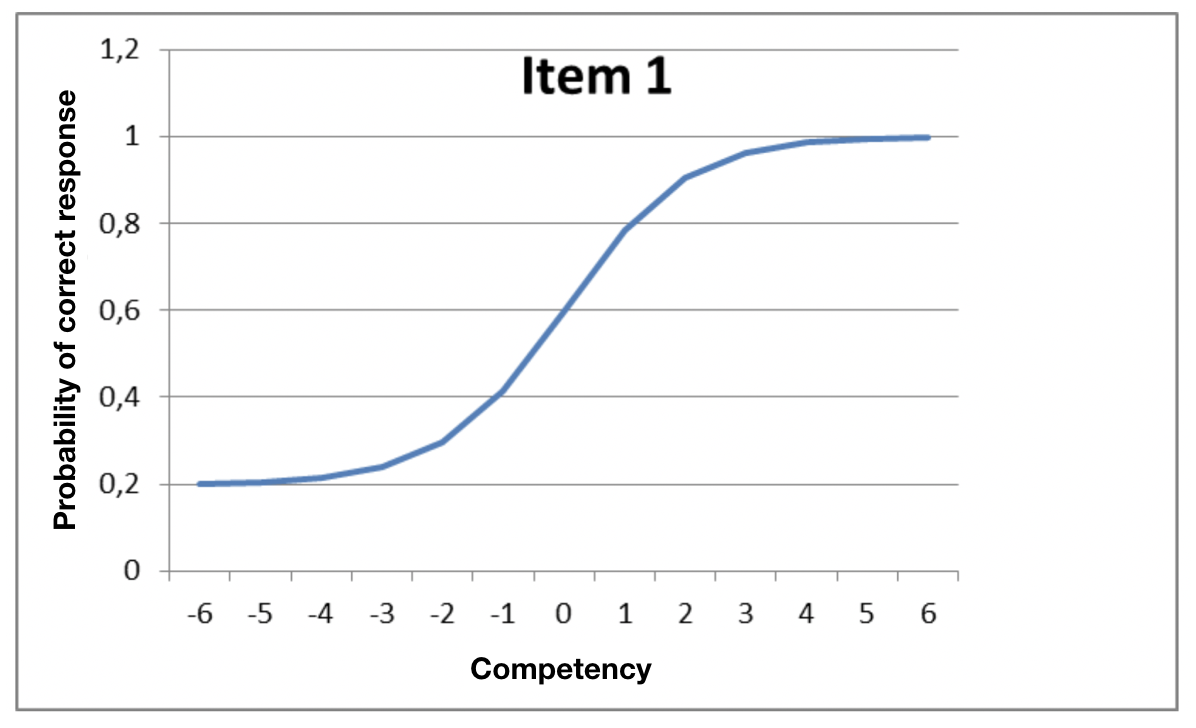
Prepona can analyze the candidates’ responses to check their behavior, identifying any possible weaknesses in the item that can be improved. The graph below shows an example of an item that is almost perfect:
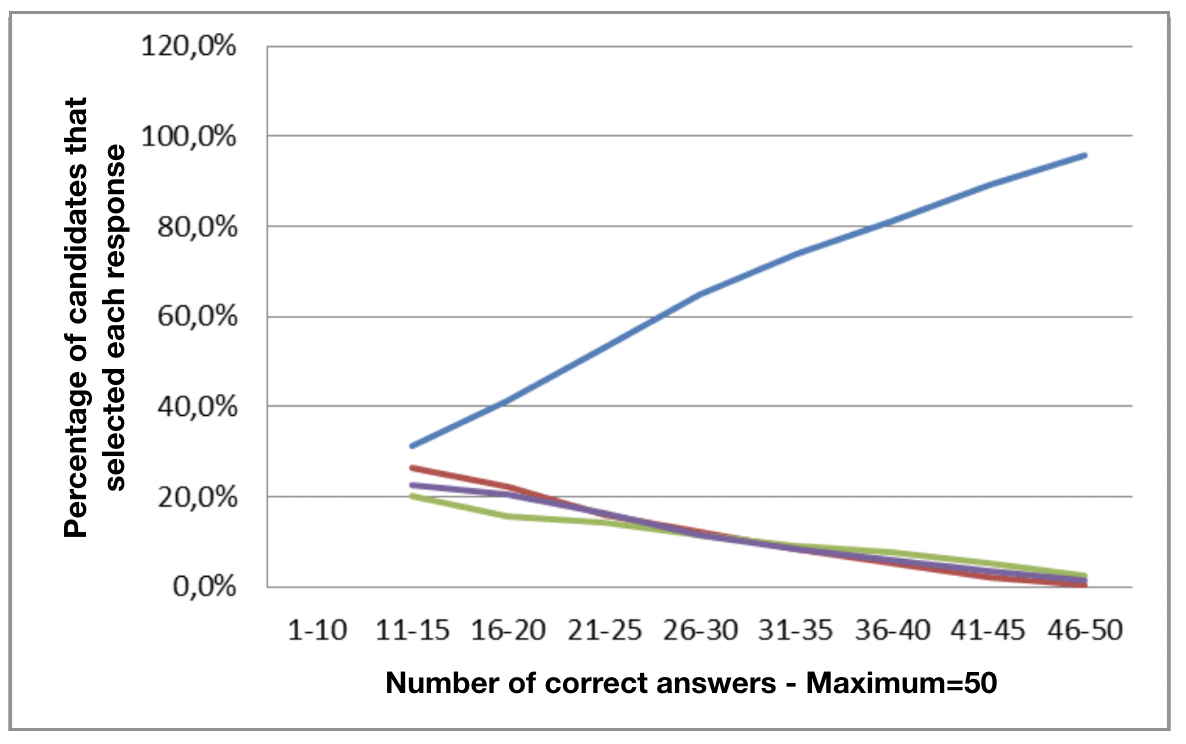
The line corresponding to the correct answer (the blue line) rises sharply whereas all the incorrect answers fall gradually to virtually zero. The weakest candidates appear to be completely lost: each wrong answer was selected by over 20% of them.
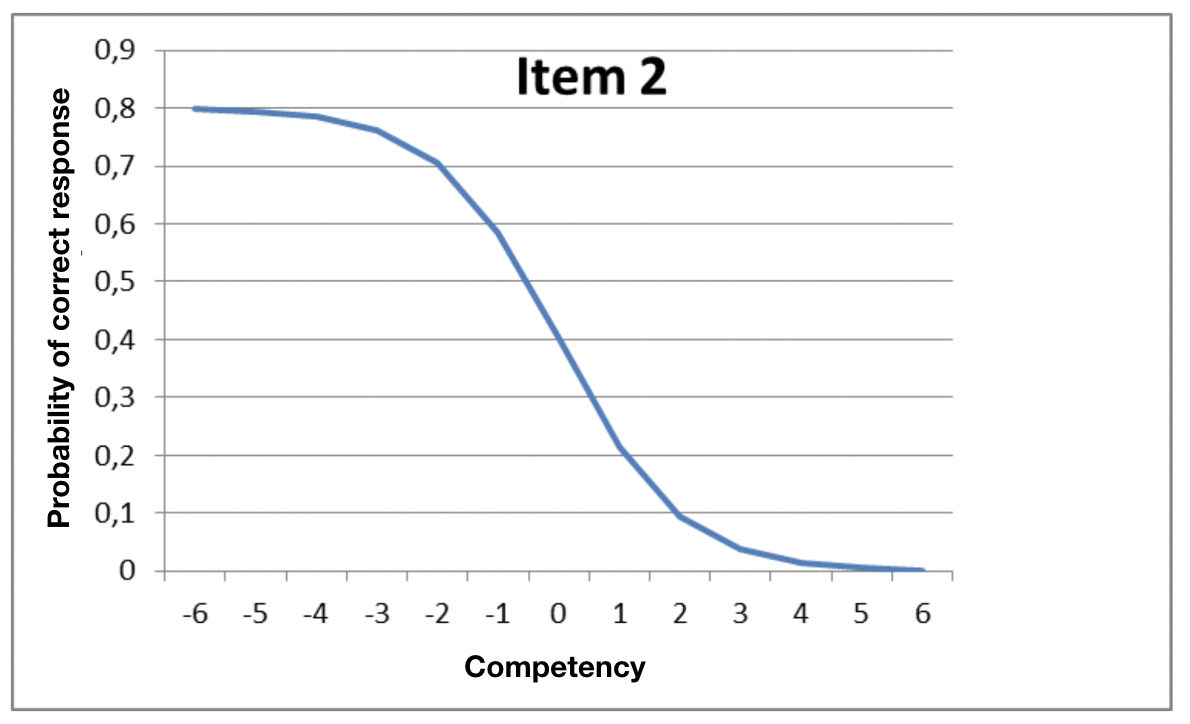
The following item should, however, be analyzed and modified, because one of the incorrect answers has serious problems.
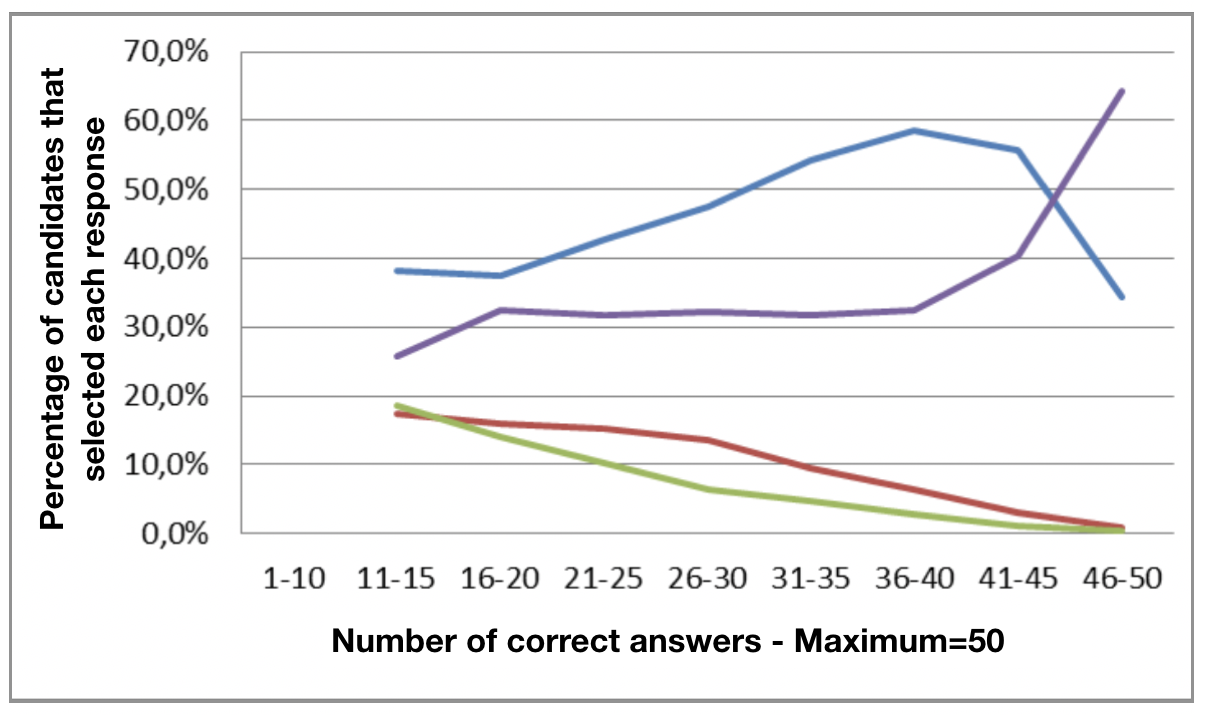
The incorrect answer represented by the blue line is attracting more and more candidates in the middle of the competency range, as their level of competence increases. The correct answer (purple line) only starts to rise for the very good candidates. In other words, the response represented by the blue line is “confusing” too many of the wrong people.
The following item displays a different behavior:
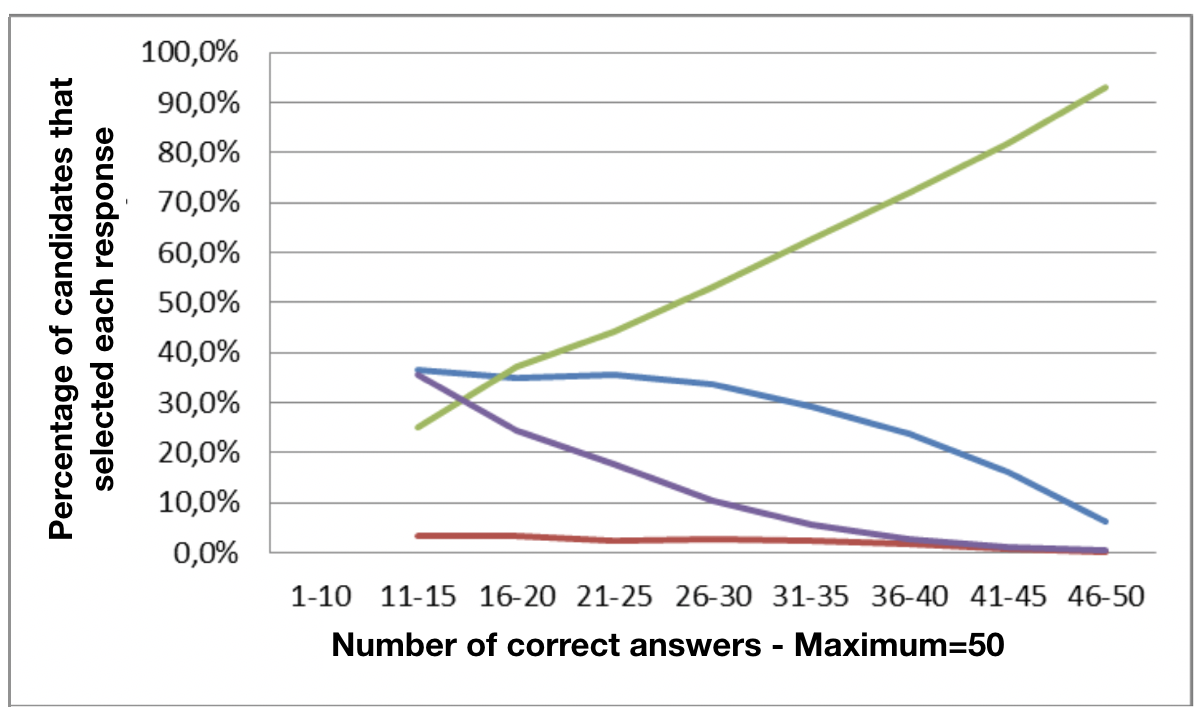
The correct answer (green line) is behaving extremely well, and two of the incorrect answers are behaving well (purple line) and satisfactorily (blue line). The incorrect answer represented by the red line, however, is not attracting anyone. A “dead” answer of this type, which is clearly incorrect even for the weakest candidates contributes nothing and should be removed or substituted.
In conclusion, a distractor analysis enables Prepona to help its partners improve even more the content of its people certification tests.